Voting as a compression problem, and the right to be heard
January 3, 2026
We often talk about politics in terms of ideology, history, or tribalism. But at its core, governance is a compression problem: how do you aggregate the distinct preferences of millions of people into a single output — policy?
In this post I restrict attention to the simplest possible setting — every policy issue is binary (Yes or No) — and ask what the geometry of compression tells us about democratic representation. A $k$-party system is a channel with $\log_2 k$ bits of capacity; issue-by-issue voting carries $n$ bits. Neither is universally right. The optimal mechanism matches the entropy of voter preferences, $H(p)$ — bundling issues that travel together, separating those that don’t. And whenever a ballot’s capacity falls short of $H(p)$, the voters silenced are predictably those whose preferences sit off the principal axis the codebook was drawn around: the system fails them not by accident but by construction.
The real world is far messier than binary issues, so the problems identified here are a lower bound on the true difficulty.
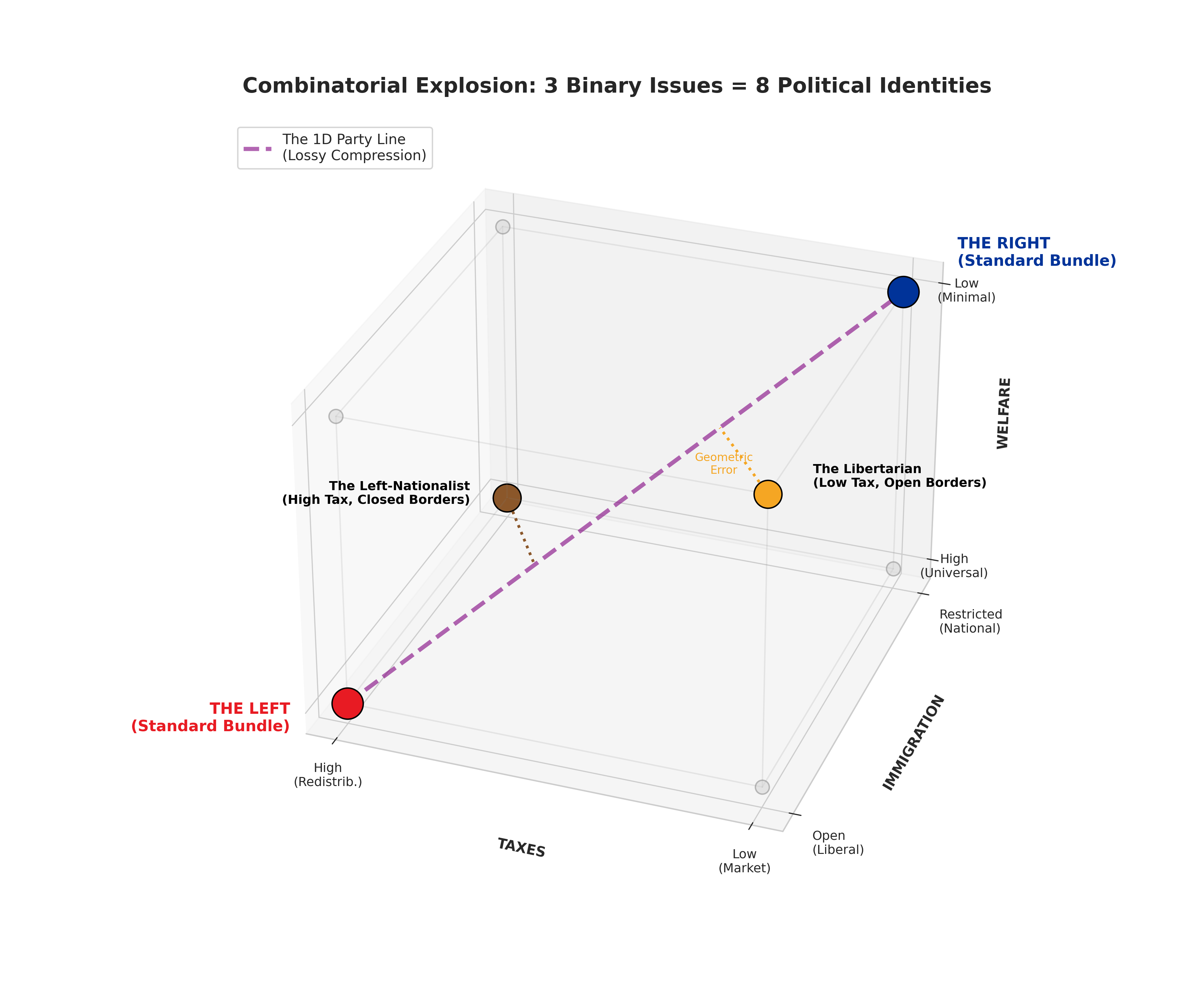
Figure 1: Three binary issues define a cube with $2^3 = 8$ corners — eight distinct political identities. A two-party system compresses this cube onto a single diagonal line (the “party line”). Under high-entropy preferences this leaves 6 of the 8 positions unrepresented; voters at those orphaned corners must choose the lesser of two evils.
1. Setup: Preferences as Binary Vectors
Suppose there are $n$ binary policy issues. For concreteness, take $n = 3$:
- Progressive Wealth Tax? (Y/N)
- Nuclear Power Expansion? (Y/N)
- Universal Basic Income? (Y/N)
Each voter’s preference is a binary vector $v \in {0, 1}^n$. With $n = 3$ issues, there are $2^n = 8$ possible preference profiles — the corners of a hypercube.
A society is a probability distribution $p$ over ${0, 1}^n$: the fraction of voters holding each preference profile.
The entropy of the electorate is:
\[H(p) = -\sum_{v \in \{0,1\}^n} p(v) \log_2 p(v)\]This measures how much “political diversity” exists. At one extreme, if everyone agrees ($p$ is concentrated on a single corner), $H(p) = 0$. At the other extreme, if preferences are uniformly distributed, $H(p) = n$ bits.
2. Parties as Codebooks: The Vector Quantisation View
A $k$-party system offers voters a menu of $k$ platforms $\{c_1, \ldots, c_k\} \subset {0,1}^n$. Each voter is assigned to the nearest party (the one matching on the most issues). This is exactly vector quantisation (VQ): we are compressing $2^n$ possible preference vectors into $k$ codewords.
The distortion of this compression is the expected Hamming distance between a voter’s true preference and their assigned party:
\[D = \sum_{v} p(v) \min_{j} d_H(v, c_j)\]where $d_H$ is the Hamming distance — the number of issues on which the voter and their party disagree.
A voter with distortion $d$ is being misrepresented on $d$ issues. This is the formal version of “the lesser of two evils.” Note that throughout, “distortion” measures distance from a voter to the nearest available platform — a representational notion — not from whichever platform ultimately wins a given election.
3. The Two-Party System as a 1-Bit Channel
In a two-party system ($k = 2$), the voter’s ballot carries exactly 1 bit of information: Party A or Party B.
But the space of preferences has $2^n$ elements, requiring up to $n$ bits to specify. The act of voting compresses an $n$-bit preference vector into a 1-bit message — a compression that cannot be lossless unless the preferences themselves live on at most two profiles. Anything richer is being forced through too narrow a channel.
This gives us a precise criterion:
A two-party system can be lossless only when voter preferences concentrate on at most two profiles — which forces $H(p) \leq 1$ bit, but is strictly stronger.
When it works: Low-entropy electorates
Suppose 50% of voters hold preference $(0,0,0)$ (“The Left”) and 50% hold $(1,1,1)$ (“The Right”). Then:
\[H(p) = -2 \times 0.5 \log_2 0.5 = 1 \text{ bit}\]A two-party system with $c_A = (0,0,0)$ and $c_B = (1,1,1)$ achieves zero distortion — every voter is perfectly represented. The 1-bit channel suffices because the electorate only uses 1 bit of the available $n$-bit space.
This is the scenario that two-party advocates implicitly assume: that political preferences are highly correlated, clustering neatly into “Left” and “Right” bundles.
When it fails: High-entropy electorates
Now suppose voters are uniformly distributed across all 8 corners. Then $H(p) = 3$ bits, but the channel capacity is still 1 bit. No matter how cleverly we choose $c_A$ and $c_B$, we must lose at least $3 - 1 = 2$ bits of information.
Concretely, with $c_A = (0,0,0)$ and $c_B = (1,1,1)$, consider the voter at $(1,0,1)$ — a “Libertarian” who wants low taxes and minimal welfare but open immigration. There is no ballot they can cast that expresses this preference. Voting for $c_B$ actively endorses the welfare expansion they oppose; voting for $c_A$ actively endorses the closed borders they oppose. There is no third option, no way to register “I want $(1,0,1)$” — the system has no vocabulary for it. The same trap catches the voter at $(0,1,0)$, a “Left-Nationalist” who wants high taxes and strong welfare but closed borders. Each is forced not merely to accept a compromise but to cast a vote endorsing a position they reject; the information that they wanted otherwise never enters the channel.
Hamming distance 1 makes this sound like a small error. From the voter’s side it is total: on the issue they were silenced on, their vote counts the wrong way.
The expected distortion for the uniform distribution with optimal two-party placement is:
\[D = \frac{1}{8}\sum_{v \in \{0,1\}^3} \min(d_H(v, c_A), d_H(v, c_B))\]With $c_A = (0,0,0)$ and $c_B = (1,1,1)$, the distances are:
| Voter $v$ | $d_H(v, c_A)$ | $d_H(v, c_B)$ | $\min$ |
|---|---|---|---|
| $(0,0,0)$ | 0 | 3 | 0 |
| $(0,0,1)$ | 1 | 2 | 1 |
| $(0,1,0)$ | 1 | 2 | 1 |
| $(1,0,0)$ | 1 | 2 | 1 |
| $(0,1,1)$ | 2 | 1 | 1 |
| $(1,0,1)$ | 2 | 1 | 1 |
| $(1,1,0)$ | 2 | 1 | 1 |
| $(1,1,1)$ | 3 | 0 | 0 |
On average, each voter is misrepresented on 0.75 out of 3 issues — 25% of their preferences are lost. And 6 out of 8 voter types (75%) are imperfectly represented.
4. The General Rate–Distortion Tradeoff
More generally, a $k$-party system provides $R = \log_2 k$ bits of representation. The relationship between rate and distortion is governed by rate–distortion theory.
For a uniform source over ${0,1}^n$ with Hamming distortion, the rate–distortion function is:
\[R(D) = n\left(1 - H_b\!\left(\frac{D}{n}\right)\right)\]where $H_b(p) = -p\log_2 p - (1-p)\log_2(1-p)$ is the binary entropy function. To achieve distortion $D$, you need at least $R(D)$ bits — i.e., at least $2^{R(D)}$ parties.
This formalises the tradeoff:
| Parties ($k$) | Bits ($R$) | Min. distortion (uniform, $n=3$) |
|---|---|---|
| 2 | 1 | 0.75 |
| 4 | 2 | 0.5 |
| 8 | 3 | 0 |
These are the achievable minima for $n = 3$ (the rate–distortion bound is asymptotic over many blocks and is tighter than what any finite codebook attains). To reach zero distortion with $n$ binary issues you need $k = 2^n$ parties — one for every corner of the hypercube.
5. The Curse of Dimensionality
The table above reveals the fundamental problem: the number of parties required for lossless representation grows exponentially in the number of issues.
For $n = 3$, we need 8 parties — manageable. But for $n = 10$ issues, we need $2^{10} = 1{,}024$ parties. For $n = 30$:
\[2^{30} \approx 1 \text{ billion parties}\]This is the curse of dimensionality applied to governance. No ballot can present a billion options. The cognitive and institutional costs make this impossible.
This creates an inescapable dilemma:
- Few parties ($k = 2$): Low cognitive cost, but high distortion — voters are systematically misrepresented.
- Many parties ($k \to 2^n$): Low distortion, but impossible cognitive and institutional overhead.
We cannot “party” our way out of this problem.
When does the curse bite?
The severity depends on the entropy of the electorate. If voter preferences are highly correlated (low entropy), most of the $2^n$ corners are empty and a small number of parties suffices. The curse bites when preferences are independent across issues — when knowing a voter’s position on taxes tells you nothing about their position on immigration.
In the extreme “impartial culture” model (uniform distribution), the entropy is maximal at $n$ bits, and the full exponential cost is unavoidable. Real electorates lie somewhere between these extremes, but any degree of independence across issues pushes the required number of parties above what is practical.
Critically, the causal direction matters. If voters’ preferences appear correlated because the party system only offers correlated bundles, then the observed low entropy is an artifact of the compression, not a property of the underlying preferences. The system may be manufacturing the conformity it relies on.
6. Matching Structure: The Right Factorisation
The exponential curse in §5 assumed every corner of the hypercube is equally populated — the impartial-culture extreme. Real electorates have structure: knowing a voter’s position on healthcare predicts their position on taxes; knowing their position on immigration tells you something about drug policy. Preferences cluster.
This reframes the question. The right thing to ask is not “bundle or unbundle?” but what factorisation of the ballot matches the conditional-independence structure of voter preferences? Two parties is the extreme of forcing everything onto a single axis. Issue-by-issue is the extreme of treating every dimension as independent. Both are special cases of one principle:
The ballot’s channel capacity should match $H(p)$ — the entropy of voter preferences.
Three regimes make this concrete.
6.1 The aligned electorate: bundling is efficient
Suppose 50% of voters sit at $(0,0,0)$ (“Left”) and 50% at $(1,1,1)$ (“Right”). $H(p) = 1$ bit.
A two-party system with platforms at these corners achieves zero distortion — every voter’s nearest party matches them exactly. Issue-by-issue voting also faithfully records every voter’s preferences, but extracts 3 bits per voter to capture 1 bit of signal. The 2 extra bits are pure overhead.
Two parties wins. When the electorate is one-dimensional, the 1-bit channel is exactly right.
6.2 The independent electorate: bundling is fatal
Now suppose preferences are uniform over all 8 corners. $H(p) = 3$ bits. From §3, two parties yield distortion 0.75 — a quarter of every voter’s preferences silently discarded. Four parties only reach 0.5. To get to zero you need $2^n$ codewords, and the cost explodes at $n = 30$.
Issue-by-issue voting matches the entropy exactly: 3 bits in, 3 bits out, zero distortion, linear cost.
Unbundling wins. When issues are independent, no amount of clever bundling helps; the only fix is to give the ballot enough capacity.
6.3 The clustered electorate: factor along the clusters
Most realistic electorates lie between these extremes. Consider 6 issues that split into two thematic clusters:
- Economic axis: {wealth tax, welfare expansion, public healthcare}
- Social axis: {drug liberalisation, immigration, surveillance}
Within each cluster, issues are tightly correlated. Across clusters they are independent — your economic leanings tell us nothing about your social ones.
Concretely, say each cluster is split 50/50 between its all-Yes corner and its all-No corner, with the two clusters drawn independently. The electorate has 4 equally-sized types:
| Type | Economic | Social |
|---|---|---|
| Progressive-libertarian | $(1,1,1)$ | $(1,1,1)$ |
| Progressive-authoritarian | $(1,1,1)$ | $(0,0,0)$ |
| Conservative-libertarian | $(0,0,0)$ | $(1,1,1)$ |
| Conservative-authoritarian | $(0,0,0)$ | $(0,0,0)$ |
$H(p) = 2$ bits.
| Mechanism | Bits/voter | Distortion (out of 6) |
|---|---|---|
| 2 parties (single axis) | 1 | 1.5 |
| 4 parties (one per type) | 2 | 0 |
| 6 issue-by-issue votes | 6 | 0 |
| 2 cluster bundles | 2 | 0 |
Two parties fail because forcing 4 types onto one axis collapses the orthogonal dimension. Issue-by-issue succeeds but extracts 4 bits more than the source contains. The clean answer is to ask each voter for two bits — a single Y/N for the economic package and a single Y/N for the social package — yielding zero distortion at exactly the entropy of the electorate.
6.4 The principle
The right ballot mirrors the conditional-independence graph of voter preferences. Bundle issues that travel together; separate clusters that don’t. The voter transmits one bit per cluster — not one bit per electorate, and not one bit per issue.
Survey data on real political opinion suggests roughly 2–4 dominant axes, not 1 (the two-party assumption) and not 30 (the impartial-culture assumption). The optimal number of distinct policy packages is correspondingly modest: a handful of conditional bundles, not a billion.
Liquid Democracy falls out as a natural refinement. If voters can delegate per-cluster, they import a more informed codebook for dimensions they don’t follow while voting directly on those they do. The total representation is a composite across clusters, rather than a single lossy codeword that bundles everything.
7. The Limits of Unbundling: Ostrogorski’s Paradox
There is an assumption hiding inside the “unbundling is fatal” argument of §6.2: that a voter’s satisfaction is the sum of per-issue agreements. This is the separability assumption, and it is what makes Hamming distortion the right loss function.
Real preferences are often non-separable. A natural example:
I support expanding welfare for families, jobseekers, and the disabled. Unless a UBI is on the table — in which case I support the UBI and reject the targeted increases.
The preference between “expand targeted welfare” and “leave it alone” is conditional on whether UBI passes. Voting on each issue independently can produce UBI and the targeted increases — a package nobody actually wanted.
The textbook version is the Ostrogorski paradox. Three blocs vote on three issues:
| Bloc | Share | Bundle |
|---|---|---|
| A | 40% | $(Y, Y, N)$ |
| B | 30% | $(Y, N, Y)$ |
| C | 30% | $(N, Y, Y)$ |
Issue-by-issue majorities give Y (70%), Y (70%), Y (60%) — outcome $(Y, Y, Y)$, a bundle no voter actually preferred. Each voter sits at Hamming distance 1, which looks fine under separable loss but is catastrophic if voters care about coherent packages over per-issue marginals.
This is where the §6 framework rescues us. Non-separable issues are, by definition, not conditionally independent — and therefore belong in the same cluster. UBI and targeted welfare are not separate issues; they are one cluster with internal logical structure that has to be voted on as a unit. The §6.4 diagnostic — does knowing position on A predict position on B? — catches this case automatically.
Ostrogorski paradoxes arise only when you over-unbundle: when you treat as independent dimensions that the actual preference structure binds together. The right factorisation keeps them bundled, and the paradox dissolves.
The mistake at both extremes is the same: imposing a structure that doesn’t match the electorate. Two-party democracy assumes one axis; pure direct democracy assumes none. Both are wrong in the same way, in opposite directions.
8. The Right to Be Heard
So far we’ve framed compression loss as average distortion — how much voters’ preferences fail to match the system’s output. But averages hide a sharper question: whose preferences are lost?
Lossy compression doesn’t lose information uniformly. It loses the information furthest from the codebook. In a two-party system with platforms on the principal axis, the silenced voters are exactly those at the off-diagonal corners of the cube: libertarians (low tax, low welfare, open immigration), left-nationalists (high tax, strong welfare, closed borders), eco-socialists, religious progressives — voters whose combination of concerns doesn’t lie on the dominant ideological axis. These are not random voters. They are systematically the people whose particular bundle crosses the lines the dominant axis was drawn to separate.
This is the structural source of disenfranchisement. When a voter says “no party represents me,” they are usually right. Their preference profile sits in a region of the cube that no codeword covers, and by construction the system cannot recover it. The feeling is not paranoia — it is the predictable consequence of routing an $n$-bit signal through a 1-bit channel.
It also explains why disenfranchisement clusters with minority status. Two-party systems optimise for the median voter along the principal axis of variance. Whoever sits off that axis loses — and the people off that axis tend to be those whose interests don’t align with the majority bundle. Ethnic minorities with policy concerns that cross the left-right divide, regional populations with distinct priorities, religious communities with idiosyncratic combinations: their disenfranchisement is not a failure of organisation but a mathematical consequence of the channel they’re forced to use.
This reframes the central question. Instead of “is the system efficient?” we should ask: does every voter have the right to transmit their preferences without distortion? A democracy that meets this standard must offer a ballot with channel capacity at least $H(p)$. Anything less is a system that, by design, silences someone.
One caveat worth stating plainly. The right argued for here is informational — the right to be heard. It is distinct from the right to be obeyed. Even under perfect issue-by-issue voting the minority loses on each issue; their preferences are recorded but not enacted. The information-theoretic argument tells you what it takes to register every voter’s preferences faithfully. Whether the system then aggregates them fairly — proportionally, via Condorcet, via supermajority on sensitive issues — is a separate question. But registering is the prerequisite. A democracy that cannot even hear its minorities cannot meaningfully claim to weigh them.
Summary
| Electorate | $H(p)$ | Optimal ballot | Bits/voter |
|---|---|---|---|
| Aligned (one axis) | $\approx 1$ | 2 parties | 1 |
| Clustered ($c$ axes) | $\approx c$ | $c$ cluster-bundles (or $2^c$ parties) | $c$ |
| Independent (all issues unrelated) | $n$ | Issue-by-issue | $n$ |
| Arbitrary $p$ | $H(p)$ | Match the factorisation | $H(p)$ |
The mathematics is simple. Preferences over $n$ binary issues live in an $n$-dimensional space, but the effective dimensionality is the entropy $H(p)$. A ballot with channel capacity below $H(p)$ loses information; above $H(p)$ wastes voter effort. Two parties is right when the electorate is one-dimensional. Pure issue-by-issue is right when issues are independent. Neither is universally right — and the universal answer is to factor the ballot to match the conditional-independence structure of preferences, bundling within clusters and separating across them.
The deeper point is not efficiency but whose voice the channel can carry. Every voter whose preferences lie off the codebook’s principal axes is, by construction, silenced — and these are not random voters, but the predictable minorities whose particular bundle of concerns the dominant axis was drawn to ignore. A democracy that takes representation seriously owes its citizens a ballot wide enough to hear them. We don’t need to choose between bundling and unbundling. We need a mechanism that can do either, dimension by dimension — and that owes a hearing to everyone, not just the median voter.
References
- Thorburn et al. (2023). Error in the Euclidean Preference Model. arxiv.org/abs/2208.08160
- Daudt, H. & Rae, D. (1976). The Ostrogorski paradox: a peculiarity of compound majority decision. European Journal of Political Research.
- List, C. & Pettit, P. (2002). Aggregating sets of judgments: an impossibility result. Economics and Philosophy.
- Cover, T. & Thomas, J. (2006). Elements of Information Theory, 2nd ed. (Chapter 10, Rate–Distortion Theory.)