How can we use ladder nets in the unsupervised setting?
May 30, 2018
Ladder nets (aka Unets) are currently achieving state-of-the art results on image to image translation, for example see here. This network architecture achieves such great results because the skip connetions allow higher frequency information, such as edges and gradients, to be easily communicated between the encoder and decoder. This is useful for image to image translation as typically we are translating between ‘styles’ (low frequency content such as palette, textures), while the high frequency content maps to the ‘content’ (see style transfer). $\textbf{Q:}$ How can we use this architecutre for unsupervised learning?
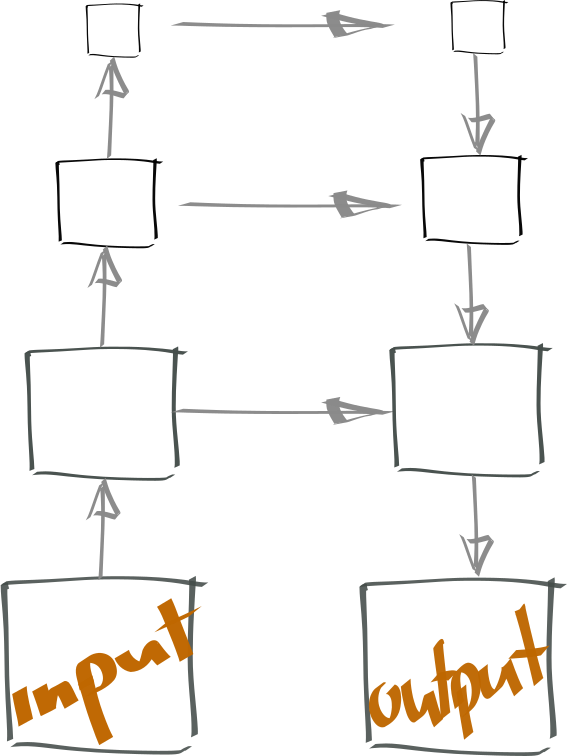
An autoencoder with skips
Given this architectures power for image processing, it would be nice to use in unsupervised setting as well. However, naive implementation of an autoencoder with these skip connections is just cheating… The skip connections allow information to be skipped straight to the output, making reconstruction rather easy.
$\textbf{Q:}$ How can we force the network to use the deeper layers? How can we constrain the capacity of the skip connections?
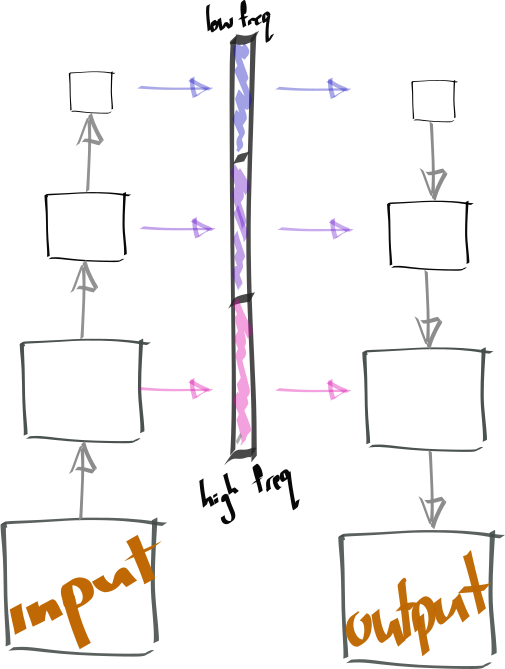
Filter the frequency content
What if we enforced constrains on the skip connections to ensure the earlier skip connections can not communicate low freqency information? A high and low pass filter.
\[\begin{align} z_{low} &= \text{avg_pool}(x)\\ z_{high} &= x - z_{low}\\ \end{align}\]

(code for generating images is in tfjs (see source). but is kinda buggy)
Structured latent space
Now our hidden space is structured. Earlier skips carry high frequency content and later skips carry low frequency content.
‘High’ level content
What do we mean when we talk about high level content? Familiar definitions include invariance to transforms, or generality, or absractness. But another valid interpretation seems to be: low frequency content. Thus we hope to capture the high level content, by forcing the information through low pass filters.
TODO.
- Explore the connection to a recursive wavelet decomposition
- Actually test at scale
The idea was Paul Matthews’, I just wrote it down.